Research
In our one-of-a-kind lab, we conduct joint research in the hardware and software domains of Brain-Inspired Computing and Circuits, ranging from low-level Memristors to high level algorithms for Spiking Neural Networks, with applications in the Wireless Communication domain and more!
This particular research setting enables us not only to theoretically contribute to Neuromorphic Computing, but also tightly couple and evaulate the algorithms on our specialized neuromorphic hardware. This greatly aids in getting the brain-inspired AI technologies closer to real-world deployment with applications in a variety of domains. Thank you for taking interest in our research; take a look below on what, why, and how we do research in our lab, and if enthusiastically intrigued, feel free to contact Dr. Yang (Cindy) Yi.
Encoders and ASIC Design

Like biological neural systems, signals can be transmitted as spikes in neuromorphic neural networks. Thus, a spike encoder is essential for a neuromorphic computing system. To better understand the functionality of a neuromorphic network, neural encoding schemes need to be carefully investigated. Such an encoding scheme refers to converting the information of input stimuli into a set of spike trains, which the downstream units can process.
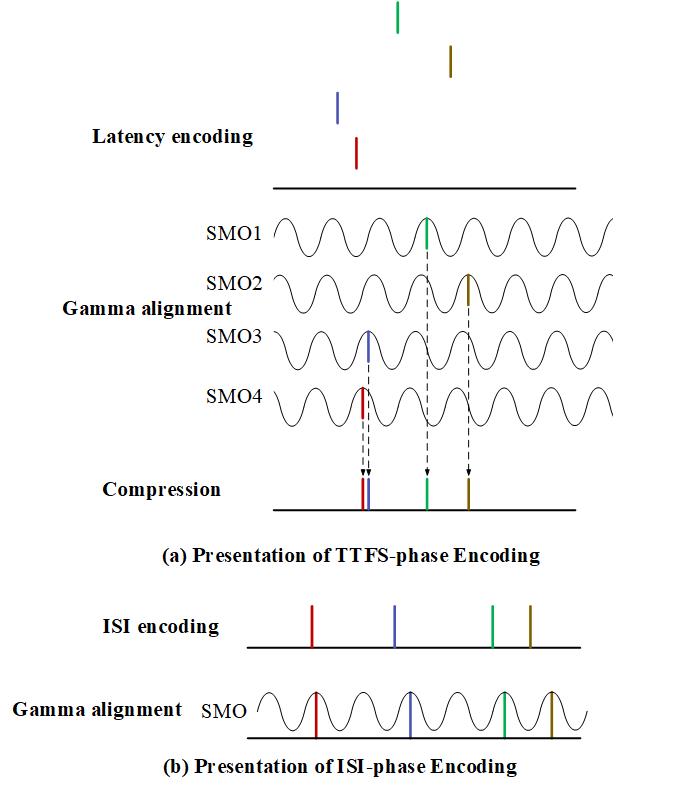
The research about encoding schemes started a few decades ago. There are two main kinds of encoding schemes, Rate Encoding and Temporal Encoding. Rate encoding is an encoding scheme that maps the input information to the number of spikes within the sampling window. Rate encoding is easier to understand and implement than other encoding schemes. Thus, it is more widely realized in software and hardware implementations than other encoding schemes. Unfortunately, this encoding scheme has the disadvantage of low data density. Since rate encoding only uses the number of spikes to convey information, the temporal patterns of spikes in encoding windows are ignored. On the other hand, temporal codes tend to transmit information with the temporal patterns of spikes, thus utilizing both the number of spikes and the firing time of the spikes. Two different types of temporal encoding are commonly investigated, the Time-to-First-Spike (TTFS) encoding and the Interspike-Interval (ISI) encoding.

With the progress of large-scale data processing applications, the demand for higher data processing capacity becomes increasingly intense. Researchers have found an encoding scheme that combines multiple schemes to increase the data capacity in biological neural systems, called the Multiplexing Encoding scheme. Besides better encoding capability, multiplexing encoding has some other advantages as well. This scheme is more stable and robust with an internal reference frame, than other encoding schemes, especially in the noisy environments. Our group has designed and analyzed the first Application-Specific Integrated Circuit (ASIC) chip of the ISI temporal encoder and the multiplexing temporal encoder (to the best of our knowledge). These encoder designs have achieved both - a high training/inference accuracy and extremely high power efficiency with reasonable design area.
Memristors-based Neuromorphic Computing

The data-intensive nature of AI applications makes them computationally inefficient to run on traditional computing architectures. Due to the large number of vector-matrix multiplication operations in the Neural Networks, a significant amount of power is spent on data movement - to and from the memory. This is a latent limitation of von-Neumann Architecture, on which a majority of conventional computing-hardware is based. The latency of this data movement between the computing/processing unit and the memory also limits the throughput performance of the system.
A Memristor crossbar can solve this issue of increased energy consumption and latency by carrying out large amounts of vector-matrix multiplication operations in-memory. As an emerging non-volatile memory (eNVM) technology, the memristor has gained immense popularity in recent years due to their ability to emulate spiking neurons and synapses to aid in the making of neuromorphic hardware. With the use of our two-layer fabricated VT memristor, we aim to develop energy-efficient Neuromorphic Computing architectures. Our work encompasses memristor-based Spiking Neural Networks, spiking Reservoir Computing, as well as in-memory computing architectures.
Algorithms for Spiking Neural Networks and Loihi
One of crucial aspects of information processing in our brain is the generation and transmission of action potentials, a.k.a. spikes. Spiking Neural Networks (SNNs) are the next generation Neural Networks which employ spiking neurons to accomplish general AI tasks. Unlike the Artificial Neural Networks (ANNs), they are inherently temporal in nature, with few works advocating SNNs to be more robust and potentially more powerful than ANNs!

So far, in our attempts to develop brain-like AI, we have been working with the conventional ANNs for long (since the start of 1940s), which are composed of highly abstracted out non-spiking neurons. The recent breakthroughs in AI can be largely attributed to the coupling of effective ANN training techniques and suitable hardwares e.g. GPUs/TPUs. But this has come at the cost of high energy consumption while training and inferencing; this is not at all scalable for edge devices or battery powered critical AI systems. SNNs on the other hand, in conjunction with specialized neuromorphic hardware e.g. SpiNNaker, Loihi, TrueNorth, etc. offer the promise of low-power and low-latency AI!
In this lab, we actively work in the field of Neuromorphic Computing to develop spiking network algorithms with a focus on their deployability on specialized neuromorphic hardware, e.g., Intel’s Loihi. We also collaborate with other (hardware) teams in this lab to develop novel neuromorphic hardware customized spiking networks for applications in wireless communication domain, apart from the general AI tasks.
Neuromorphic Computing in Communications

Brain-Inspired computing, such as Reservoir Computing, provides a new paradigm of data-driven algorithm design for communication systems. The rich dynamics behavior of Reservoir Computing may help build simplified signal detection algorithms using efficient training techniques.
Future communication systems, such as the 5G/6H wireless networks, face many new design and implementation challenges. For example, traditional model-based algorithms may not scale well with massive MIMO antenna systems and have model mismatch problems in real-world environments. Furthermore, their high complexity hinders power efficiency for mobile and IoT applications.


We have adopted Echo State Networks (ESN) and demonstrated their superior performance in a real-time Software-Defined Radio (SDR) testbed. Our ESN-based MIMO-OFDM symbol detection system is more resilient and power efficient than conventional algorithms widely used in the current 5G systems. We are also exploring other types of Neuromorphic Computing techniques for applications in wireless systems.
Neuromorphic Computing and FPGA

Neuromorphic Computing is based on the non-von Newman architecture, which breaks the memory bottleneck of the traditional computing chips to achieve low-power, low-cost, and low-latency design. FPGA-based Neuromorphic Computing design focuses on the hardware implementations of neuromorphic computing systems and architectures on FPGA and the associated optimizations on it.


Due to the novel architecture of neuromorphic computing, it has better computation efficiency on temporal tasks than traditional Neural Networks such as Recurrent Neural Networks (RNNs). However, neuromorphic computing chips such as Intel’s Loihi, are still not mature enough to implement all kinds of circuits. Many ideas about the architectural optimizations on the neuromorphic computing systems need to be verified in time, which is easily doable on FPGAs - a reconfigurable and mature platform for circuit design.
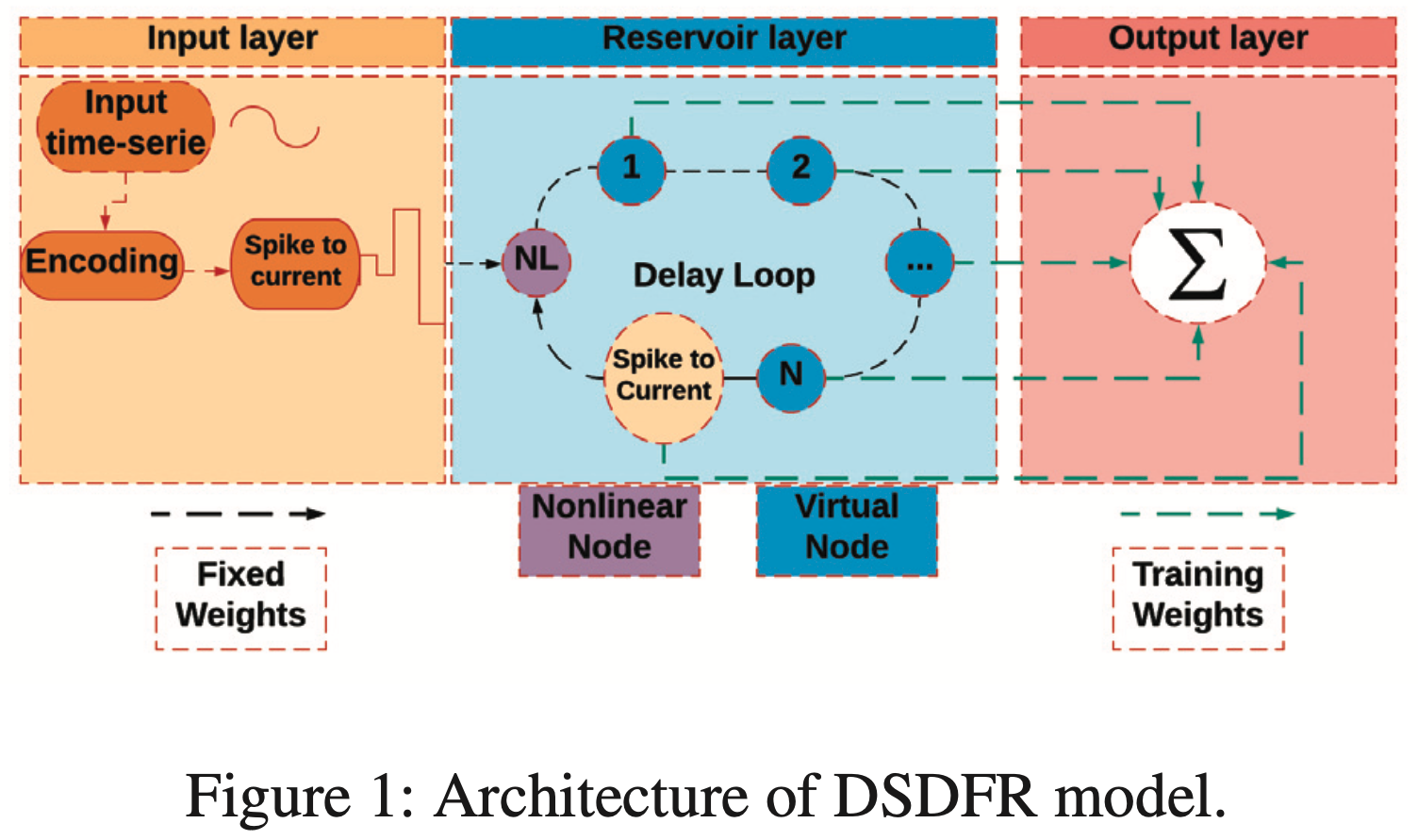
We have been working on new architectural designs of the typical models of recurrent networks such as, Echo State Network (ESN), Delayed Feedback Reservoir (DFR), etc., adapting them to neuromorphic systems with their designs implemented and verified on the FPGA platforms.